
Motoneurone disease (MND), called Amyotrophic Lateral Sclerosis (ALS) in the US, is without doubt a devastating neurodegenerative disease. The standard pharmacological treatment for the condition is riluzole, which results in a modest but definite slowing of disease progression. Since its inception in the 1990’s, many studies have confirmed its efficacy, showing that it slows the deterioration in quality of life rather than just prolonging survival. It costs around $50 to $200 dollars a month.
Unfortunately, over the subsequent 30 years, no better treatment has been identified. However, there have been recent advances in gene therapy that may have a bearing on the condition.
About 2% of all cases of MND are due to a mutation in the SOD1 gene. Most cases are sporadic and not as readily amenable to gene therapy. Tofersen is an antisense oligonucleotide that binds to the SOD1 mutation gene. It is somehow targeted by cell membrane receptors that trigger endocytosis. Then there is leakage from the endosome into the cytosol where it binds to SOD1 mRNA to prevent translation; RNAase recognises it as a hybrid and destroys it. The result is that it downregulates the protein product of the SOD1 gene by 80-90%. As an autosomal dominant mutation, no protein is better than mutated protein. SOD is one of three antioxidant enzymes for clearing superoxide and converting atomic oxygen into hydrogen peroxide; presumably the other two can do the job.
The drug has to be delivered into the cerebrospinal fluid to work. This entails a course of fortnightly intrathecal (lumbar puncture) injections for 6 weeks followed by monthly injections. It is not clear if this is to continue indefinitely.
To obtain the treatment privately, including the infrastructure required for intrathecal delivery, has been estimated at €450,000 a year! While the drug is in a trial stage, the drug company Biogen are offering the drug itself for free.
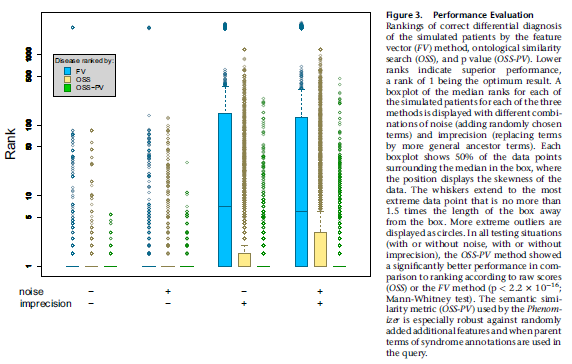
In our journal club, we discussed preventative therapy; we found that the penetrance of pathogenic mutations is significantly variable and averages a little over 50%, though some mutations have much higher penetrance. We are not going to deliver intrathecal injections monthly when someone might not ever get the disease.
The initial phase 3 trial of tofersen, which they called VALOR, had 108 patients enrolled and was completed by 97. Two thirds of the patients had treatment, the remainder placebo. It ran for 28 weeks from 2019-2021 and did not reach significant improvement at end point.
The topic of this journal club is an open label follow up of the same patients, which came to the opposite conclusion.
It is worth going into more detail on the original study. This primary end point was the score on the ALS functional rating scale in a subgroup of patients predicted to have faster disease progression, presumably so that they could see an earlier difference from treatment.
The range of this scale is 0 to 48 and after 28 weeks the deterioration in the treated group was 7 points, and in the untreated group 8 points; the 95% confidence interval of the difference was -3.2 (drug worse) to 5.5 (drug better), p=0.97. This lack of significance could hardly be clearer and moreover one point difference on a 48 point scale does not sound like a meaningful benefit even if it was significant.
The 95% CI for vital capacity difference was -3.5% to +19 % while hand held dynamometry strength testing was negligibly different. The rates of death or permanent ventilation in the two groups was 2/21 on placebo and 4/39 on treatment.
They described LP related adverse events as common and serious adverse events occurred in 7% of tofersen recipients. These were mainly myelitis (inflammation of the spinal cord), radiculitis and papilloedema.
In this paper, they also discussed one year data, which included a 6-month open label extension period, meaning that both originally treatment patients and the placebo patients now received treatment. These data were pooled over all the patients, not just the faster progressing ones. They suggested that there might be delayed benefit, but this did not change the study’s overall conclusion.
They didn’t go into detail on the combined results for rapid deteriorators and slow deteriorators at 28 weeks, the end of the placebo period, because they said they didn’t plan to adjust the statistics for multiple comparisons, but on looking at their graph, it appears to be about -4 points deterioration on the scale in the treated patients versus -6.25 for untreated. The % change in vital capacity looked significantly worse in untreated, and there was no significant difference in hand dynamometry, and no significant difference in rates of death or requiring permanent ventilation.
The topic for this journal club was a longer open label extension up to 3.5 years. Of the original 108 patients, 94 completed the initial 28 week study, but only 46 completed the open label extension!
This should send one immediately diving into why this was the case. By the end, there were 34 patients still left in the early start group, and 12 in the delayed start group (the original placebo group). The original numbers were 63 and 32.
In the delayed start group, 21 discontinued – 1 adverse event, 6 withdrawn consent, 6 death, 5 disease progression, 3 other.
In the early start group, 29 discontinued – 1 adverse event, 1 lost to follow up, 4 consent withdrawn, 14 death, 8 disease progression, 1 other.
So more patients stopped due to death in the early treatment group (22.2% versus 18.75%).
There was reduced csf SOD1 protein in the treatment group, and neurofilament light chain, but the latter equalled out by the end of the trial. It is often wishful thinking to use biomarkers as a surrogate for clinical outcome. They might be more useful in normal clinical practice to monitor individual patients.
The early start group (both predicted rapid deteriorators and slow deteriorators) had 9.9 points deterioration on the functional scale versus 13.5 points, and -13.8% reduced vital capacity versus -18.1%. The authors did not highlight the statistical results, saying the study was not powered to show this, but referred to “numerically less decline” in the early treatment group. Clearly, they were not significantly different. The p value for functional score was 0.14, that for vital capacity was 0.44 and dynamometry 0.55. Indeed, on the graphs, the vital capacity figures appeared to come together by the end of the trial and the dynamometry figures never really separated in the first place.
Regarding survival (avoiding death or permanent ventilator dependence), the hazard ratio was 0.64 (0.28 to 1.46 95% CI), so clearly there was no evidence of shortening of life in the delayed treatment group. On the Kaplan Meier survival plots, there were some strange findings. Overall, there was very little “numerical” (to use the authors’ terminology) difference at 28 weeks or 3.5 years, but between those times the delayed start had a worse trend. In predicted milder patients, early starters had a major worsening by the end of the plot, and in predicted severe patients, there was initially no difference (as reported in the first study), but when the delayed start patients later got treatment, they fell off more rapidly instead of catching up! This is probably explained by the tiny numbers of patients being analysed.
Statistical adjustments were apparently made for riluzole use, which might have varied between groups. We did not go into detail on what these were, but clearly a treatment which is of proven benefit might confound a study on one which is of no proven benefit when originally compared with placebo.
So, in essentially the same trial, the authors report no difference between treated patients and untreated patients, and that there were significant adverse events, but when the untreated patients later receive treatment, they say they are worse off after 3.5 years (“numerically” worse not statistically worse).
The stated purpose of the study was to compare early treated versus delayed treated patients. Yet the authors reported that the study, conducted over years in many centres across a number of countries, was not powered to show differences between groups. There appeared to be no clear hypothesis beyond this. Normally, in a delayed start protocol, the hypothesis is that there is a symptomatic benefit and disease modification benefit and if the delayed start group never catches up, it is presumed there was originally some enduring neuroprotection. It is of course difficult to test such a hypothesis when the treatment shows no symptomatic benefit in the first place.
Instead, the authors projected a comparison with what they estimated in other studies to be the natural history when untreated. This is not a randomised placebo controlled study but an observation on two completely different uncontrolled samples collected in different studies.
The conclusion was the opposite of their own initial VALOR study; now, by comparing two groups, both of which have been receiving the same treatment for years, they have “demonstrated the benefit of toferson in SOD1 ALS and a clear rationale for its use“.
The reason for these apparent contradictions, which the paper glosses over, seems to be that the benefits of treatment may have been in the opposite group to that they expected, namely in milder cases. As expected with delayed treatment, the two groups then converged, though there was a non statistically significant suggestion of maintained advantage in the functional scale in milder patients who had earlier treatment. There was certainly no benefit in death/ permanent ventilation.
The UK MND association, who stated they had met with Biogen the drug company, reported on 17th March 2025, “Tofersen gives not just a glimmer of hope to people with SOD1 MND, but a future. It is the difference between life and death. The drug itself costs nothing at the moment – yet we risk people dying for want of the NHS not being able to pay for the cost of administering it.”
The inference drawn here is different. A study was conducted on a rare subgroup of MND patients. To achieve a quick result they focused on a subgroup of patients predicted to show rapid deterioration. They seemingly could not recruit enough patients across multiple centres in many countries. There could not have been a clearer negative result (p=0.97). Ethical approval was probably contingent on the placebo arm getting the treatment later, and so there was an open label extension regardless of the results of the study. Pooling the data from the minority of patients who continued to have the intrathecal injections and who were still alive (there was a greater proportion of drop out due to death in the early treatment group), there was a non significant trend in one of the measures for a benefit in patients who had started earlier.
Treatment for such severe conditions is inevitably emotive, especially when there have been no pharmacological advances for 30 years. But that does not constitute a waiver in respect of permission to rely upon “numerical” differences and comparison with natural history in other populations. For end of life conditions that typically carry at least as devastating a prognosis as that of MND, the NHS applies a higher limit of QALY (Quality Adjusted Life Years) of £50,000; this is the cost of an extra year of perfect health that can be afforded. Even relying upon numerical non-significant results, the stark facts are that the placebo controlled section of this study showed a 1 point improvement in a 48 point scale and cost €450,000 a year and requiring 12+ lumbar punctures. The open-label extension that showed a “clear rationale for use” revealed about 1 point improvement per year over around 3 years.
We all desperately hope for effective treatment for neurodegenerative conditions such as MND. There is a risk that the sheer cost and infrastructure involved in treating this 2% of patients with MND with tofersen is a distraction from finding such treatment.






 Background
Background